 |
|
For this set of questions, the goal was to ascertain how hard it would be for an existing user to start using Unicode alongside already installed data.
Is a New installation required? This would be the case if a new master device, database, or other separate data storage space must be created to use Unicode. This is the case for most of the solutions that offer UTF-8. Sybase SQL Server requires a new UTF-8 database device to be created. Oracle and SQL Anywhere require a new database to be created with UTF-8 as the default.
If a new installation or database is not required, then is Reconfiguration or upgrade allowed of an existing installation? This is the case for all implementations that enabled Unicode as a separate datatype. ADABAS D and Interbase use SQL3 syntax. Microsoft SQL Server, Teradata, and a future version of Sybase use a new datatype name. IBM DB2 and a future version of Oracle use existing datatypes configured to hold and process Unicode (GRAPHIC and NCHAR respectively).
None of the database vendors provides In-place data conversion of non-Unicode data to a Unicode form. The suggested solution is to unload a database, set it up as a Unicode database, and reload the data, letting the various conversion mechanisms transform the data, or use SELECT INTO from a non-Unicode table into a Unicode table with either implicit or explicit conversion.
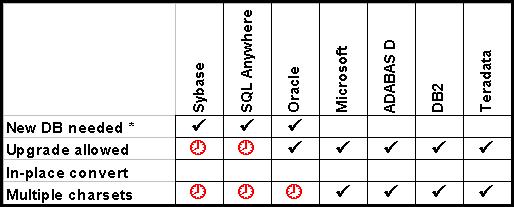
* A new data space will not be needed when UCS-2 datatypes are added in a future release.
The clock symbol indicates availability in a future release.