 |
|
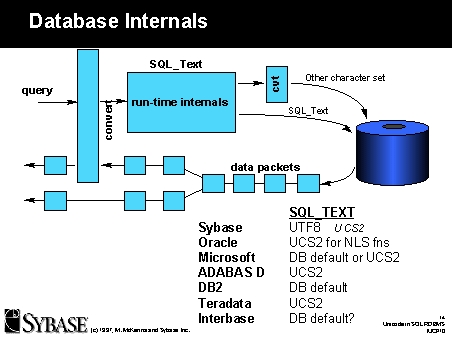
How is the data processed internally in a Unicode-enabled database server? In the SQL Standard, the character encoding used for query processing and character handling must be a superset of all expected characters that the server will handle. Known as SQL_TEXT, this becomes the default for use in the database kernel. Based on this survey, for a Unicode-enabled database system, SQL_TEXT may be UTF-8, UCS-2, and sometimes a single- or multi-byte encoding (DB2).
This slide illustrates data in any character set being converted into SQL_TEXT and the query being processed. The subsequent data accesses are done either in SQL_TEXT, if it is the same as the data storage encoding, or converted to another character set that resident data is encoded in. The query results may or may not be converted into a client character set depending on the implementation and what datatypes the results are bound to.
A few of the vendors at present use multi-byte character handling code to process UTF-8 for a like-configured installation (Sybase SQL Server, SQL Anywhere, IBM DB2). Others map all data into UCS-2 before the query is even parsed (Teradata, ADABAS D). Others use a hybrid approach, converting into UCS-2 as needed for character handling (Oracle 8.0's NLS sub-system runs entirely in UCS-2 no matter what the default character set is for the database). Its unclear what Interbase does. It is interesting to note that the Microsoft SQL Server development team had to port many of the Unicode libraries of Windows NT to Windows 95 to allow the Unicode datatype to exist on servers targeted for the Win95 platform.