Unicode String Functions
It came as no surprise that if a database is configured for a character
set with certain attributes, then its string predicates behaved predictably
in terms of all length-oriented functions (substring, concatenation, truncation,
etc.), case-mapping, binary string comparison and range functions (<,
=, >, between, etc.). This is true for all vendors that support any
encoding of Unicode.
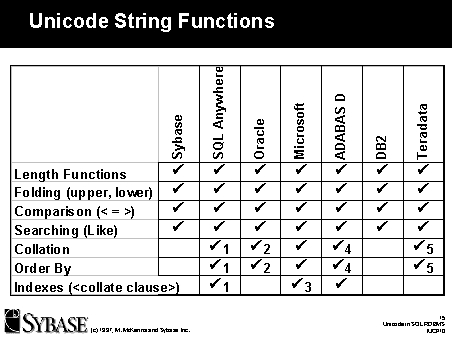
The differences appeared with respect to non-binary collations and comparisons
of Unicode data. Not surprisingly, this is an area of the SQL Standard
that is at times vague and leaves many functional details to be "implementation
defined". Sybase SQL Server and IBM DB2 do binary order sorting on UTF8
data.
- With SQL Anywhere, collations for UTF8 are based off an ordered list
of the first byte. The binary value of following bytes is used to break
ties.
- In Oracle, non-binary collation, ORDER BY, and comparison must be done
using the NLS_SORT functionality to specify a sort order. Indexes are in
binary order.
- The upcoming Beta version of the Microsoft 7.0 SQL Server has the same
limitations of the CHAR datatype of the 6.5 version. Only one collation
for all comparison operators and indexes per installation is allowed. It
is assumed that the UCS2 collation can be different from the CHAR datatype
collation, however.
- ADABAS D allows collations to be based on the binary ordering of other
character sets understood by the database kernel. Cultural based sorting
is being developed for a later release.
- Teradata sets collations and comparisons on a per session basis, following
the XPG4 model.